Natural Language Interfaces (NLI) for Databases- Part 2




Where we Left ?
This is the second part of the article: Natural Language Interfaces (NLI) for Databases –Part 1. In the first part, we discussed in detail about the first two categories of NLIs, Keyword-based and Pattern-based NLI and took examples of both of them .
As a quick recap, keyword-based systems can be enough to answer simple queries. Because they based only on the keywords. Pattern-based NLI on the other hand can be an extension of it and have a dictionary with the trigger words.
In this part we will going a step further than previously discussed systems. We’ll discuss about Parsing-based and Grammar-based NLIs.
3) Parsing-based NLI:
It’s aiming to understand the grammatical structure of the query through parsing the input query and use the generated information. The grammatical structure used to identify the long-range dependencies, which can’t be captured with simple patterns.
As an example of these systems there is ATHENA. It uses the most NLP technologies, and is an ontology-driven NLI for relational databases. It associated a set of synonyms with each ontology element. So It is based on mapping between an ontology and the relational database and can take a full English sentences as an input.
ATHENA uses an intermediate query language in order to translate the input query into a SQL query.
As the first step, ATHENA uses the ontology evidence annotator that maps the input to a set of ontology elements. The five types of this possible mapping are: metadata, translation index, time range expressions, numeric expressions, dependencies.
Then Provides a ranked list of interpretations. Which is a set of ontology elements provided by the first step. Each interpretation will be represent as a set of interpretation trees (iTree). Which is a subtree of the ontology.
The translating into SQL query :
ATHENA generates a single iTree. It can consist of a union of multiple iTrees or a single iTree. The third step uses that to generate an intermediate query using the Ontology Query Language(OQL). The structure of an OQL query is similar to SQL. And it used in the final step to translates the OQL into a SQL query.
The biggest strength of ATHENA is use the ontology as an abstraction of the relational database. Beside ATHENA can handle one-level nesting in the input query.
On the other hand, Querix allows query an ontology. But it uses a syntax tree to extract the input. Using the main categories of words: verb (V), noun (N), preposition (P), wh-pronoun and conjunction (C).
Querix use the Stanford Parser to generate a syntax tree, This parse tree of the sequence is called query skeleton. And Querix only uses this query skeleton side by side with the synonyms to translate the input query into SPARQL.
After extract the query skeleton, It enhances all nouns and verbs with synonyms provided by WordNet.
The simplicity of Querix can reduces the number of queries that can be handled, since they Constrained to a predefined syntax.
For higher level in parsing ,
There is USI Answers, is an NLI for semi-structured data and used for database that consists of multiple databases. In contrast to the previous parsing-based NLIs, USI Answers didn’t relay on parse tree, but it uses NLP technologies, such as NER, PoS tagging, lemmatization and dependency parsing. Furthermore, USI Answers uses a learned model.
BioSmart :
The Final examples of this type, BioSmart uses a syntactic classification of the input query. The system has three query templates to define the input queries. And uses the Stanford parser to parse the input query then tries to map the resulting parse tree to one of the predefined query templates.
This can be a weakness of BioSmart, if the system cannot match the input query to those predefined query templates, it is not able to translate it to SQL query.
4) Grammar-based NLI :
The core of the Grammar-based NLIs is a set of rules, grammars that define the queries that can be answered by the system. It also uses those rules to give the users suggestions for complete the queries during typing!
But as it is obvious grammar-based systems are highly domain-dependent and all the rules need to be written in details by an expert.
Let’s discuss TR Discover as the first example. TR Discover translate an English sentence into SQL or SPARQL. It is either used for ontologies or relational databases.
The first step is to parses the input into a First Order Logic (FOL) representation as an intermediate language.
Example of the parse tree for the FOL representation of an input query :
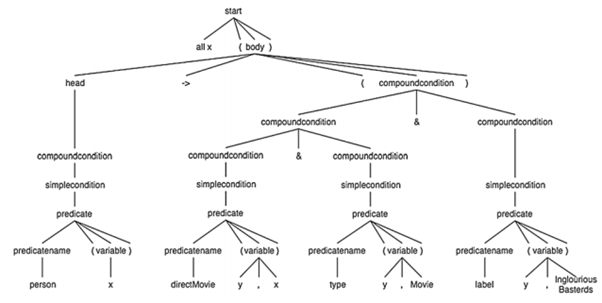
In case there are multiple ways to that input, the system will choose the first one. Then the “FOL parser” takes a FOL representation and the grammar, then using ANTLER it generates a parse tree.
The last step is to translate it into an executable SQL/SPARQL query using in-order traversal of the parse tree.
The Cons of TR Discover are that synonyms are not handled in proper way , negations can only use for SPARQL and quantifiers cannot be used.
Ginseng , No need for intermediate language
In contrast, There is Ginseng (Guided Input Natural language Search ENGine) which is a guided input NLI for ontologies. Unlike TR Discover, Ginseng does not have an intermediate language . Instead the parsing process translates directly into RDF Data Query Language (RDQL).
It uses two categories of the grammars:
1. Dynamic grammar rules:
Which are generated from the OWL ontologies.
2. Static grammar rules:
It provides the basic structures of the sentence and phrases for input queries using about 120 domain-independent rules, most of them empirically constructed.
Compared to TR Discover, The presence of these rules together lead to an easier adaptability . The Cons of the grammar rules that they need to cover all possible ways of the input query.
The Conclusion :
In general, the keyword-based NLIs are the least powerful and can only be enough to answer simple queries. That because they expect just keywords. To solve more complex queries that may involves something like aggregations, we can use an extension of keyword-based systems which is Pattern-based NLIs, they have a dictionary with trigger words to answer this kind of queries.
To answer queries with higher difficulties that may include subqueries, Parsing-based NLIs are able to answer these types of queries using dependency and trees. Still these systems are using trigger word dictionaries in order to solve aggregations, Which cannot be a general solution.
Grammar-based systems are the most powerful ones by offering dynamically applying of the rules. The huge cons of it that they are highly dependent on the handcrafted rules and grammars that are manually designed by experts.
The Machine learning approaches for NLIs, Still can be a great solution too!
For further reading : A comparative survey of recent natural language interfaces for databases .